前回までの記事ではE-R図を用いて概念データモデルを作成する方法について見てきましたが、今回からは、論理データモデルのひとつである関係データモデル(関係モデル)について見てきます。まずは、論理データモデルについて復習しましょう。
論理データモデルとは
データベーススペシャリスト試験が想定しているデータモデルは以下の3つがあります。
- 概念データモデル
- 論理データモデル
- 物理データモデル
データベース設計は基本的に上記の順番で行います。その真ん中に位置する論理データモデルは、概念データモデルを、使用するデータベースの種類を前提に、再整理したデータモデルです。そのため、論理データモデルの種別は、データベースの種類別に、階層モデル、ネットワークモデル、関係モデルの3つになります。データベースの種類は左記3つ以外にもありますが、試験にはほとんど出題されません。記載した3つの内でも、試験に出題されるのは関係モデルがほとんどです。
関係モデルは、関係スキーマもしくはテーブル構造を用いて表記されます。
関係モデル
関係モデルとして定義されている「関係」は、データ構造を平坦な2次元の表によって定義するモデルで、現在最も広く利用されているデータベースモデルです。
関係モデルでは、表を関係名(そのまま表名ということもあります)、行をタプル、列をカラムと呼び、複数の表に存在するデータ同士の関連は、主キー同士または主キーと外部キーによって行われます。
関係スキーマは、関係に含まれる属性名とその組み合わせです。表記ルールは試験問題冊子の最初のページに以下のように示されています。
関係名 (属性名1, 属性名2, 属性名3, …, 属性名n)
※関係を、関係名とその右側のカッコでくくった属性の並びで現す。これを関係スキーマと呼ぶ。
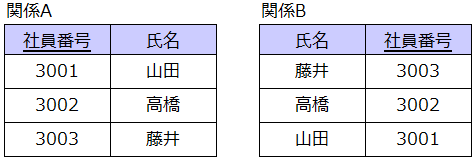
タプル、属性名の順序に規則性はありません。つまり、下図の関係Aと関係Bは同一のものとなります。
概念データモデル(E-R図)同様、午後試験の頻出テーマとなっているため、試験対策には必須の分野です。特に難しいと感じるところが通常の業務では出てこない用語や言い回しがたくさん使われることです。例えば、「関数従属は、「項目Xの値を決定すると、項目Yの値が一つに決定される」というような事実が成立するときに使われる」といった説明や、「第1正規形でかつ、非キー属性のすべてが、全候補キーに対して完全関数従属している関係を、第2正規形という」といった定義文を暗記し、意味を正しく理解しなくてはいけません。